/首页
/开源
/关于
关于mysql的select count(*)和select c
发表@2018-09-13 09:15:21
更新@2023-01-21 22:47:40
###### 事情是这样的 , 看到一个小伙儿写了这样一条sql语句 : select count(id) from user . 我就多问了两句 :“ 此为何意? ” , 小伙儿说 : “ 计算一下总数 , 做分页 ” , 我就接着问 : “ 你为啥不用select count(*) ” 。 小伙儿说 : “ 我感觉这样快啊 , 毕竟id是主键索引 ” 。 ###### 呵呵 , 愚蠢的人类总是在想当然 。 :tw-1f437: ###### 在mysql中 , count()一般来说有两个作用 , 而这两个作用听起来又好像是一回事 。 第一个作用是计算某列的非NULL值的数量 , 第二个作用就是统计数据表中的行数 。 ###### 误区一 : count(col)比count(*)快 。 然而并不是 , 当你需要计算表中总记录条数时 , 永远选择后者 , 简单理解 , 效率更好 。 ###### 误区二 : count(*)会展开所有列 , 然而并不是 , 事实上是mysql会忽略所有列 , 直接统计记录条数 。 而不是大家想象中 , 将表中的所有列展开 , 星号不是所有列的通配符 , mysql会直接返回总行数 。 ###### TIPS : count(col)计算的是col中非NULL的总行数 , 假如有一下mysql表 :  ###### 注意 , account字段默认值为NULL . 我先通过执行insert into account( account ) value('a')向表中插入100000条数据 , 然后再通过insert into account() value()向account表中插入三条account为NULL的语句 , 那么select count(*)则应该是100003 , 而select count(account)则为100000条记录 . 验证结果下图所示 : 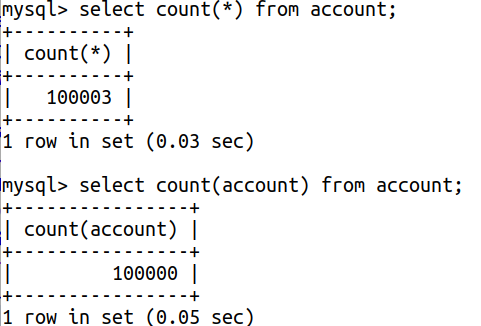 ###### 如果你依然坚持使用select count(col) , 有如下说法 , 如果当该col不可能为NULL的时候 , mysql则会直接将用count(*)代替了count(col) . ###### 所以 , 最后说到底 , 如果你真的想迫切地想优化count(*) , 可能只能通过kv缓存了 , 只不过这样 , 你总是会损失该数字的精确度 .
