/首页
/开源
/关于
swoole的协程是个什么鬼
发表@2018-09-13 09:15:22
更新@2023-01-21 22:47:40
swoole的用法实际上对于大多数新手来说一直并不怎么友好,其实这不怪swoole,只能怪萌新们确实底子不够,有些东西理解起来可能真的比较困难。今天斗胆尝试引入一个应用场景和简单的代码案例来做个简单的入门,算是抛砖头引和田玉吧。  老韩wiki.swoole.com以及一些社区中一直说swoole既可以同步又可以异步,我找一些原话,你们感受一下: > Swoole不仅支持异步,还支持同步。什么情况下使用同步,什么情况下使用异步。这里说明一下。 我们不赞成用异步回调的方式去做功能开发,传统的PHP同步方式实现功能和逻辑是最简单的,也是最佳的方案。像node.js这样到处callback,只是牺牲可维护性和开发效率。 但有些时候很适合用异步,比如FTP、聊天服务器,smtp,代理服务器等等此类以通信和读写磁盘为主,功能和业务逻辑其次的服务器程序。 继续引用凑行数: >#### 异步的优势 高并发,同步阻塞IO模型的并发能力依赖于进程/线程数量,例如 php-fpm开启了200个进程,理论上最大支持的并发能力为200。如果每个请求平均需要100ms,那么应用程序就可以提供2000qps。异步非阻塞的并发能力几乎是无限的,可以发起或维持大量并发TCP连接 无IO等待,同步模型无法解决IOWait很高的场景,如上述例子每个请求平均要10s,那么应用程序就只能提供20qps了。而异步程序不存在IO等待,所以无论请求要花费多长时间,对整个程序的处理能力没有任何影响 #### 同步的优势 编码简单,同步模式编写/调试程序更轻松 可控性好,同步模式的程序具有良好的过载保护机制,如在下面的情况异步程序就会出问题 Accept保护,同步模式下一个TCP服务器最大能接受 进程数+Backlog 个TCP连接。一旦超过此数量,Server将无法再接受连接,客户端会连接失败。避免服务器Accept太多连接,导致请求堆积 最后的引用: >swoole_http_server继承自swoole_server,是一个完整的http服务器实现。swoole_http_server支持同步和异步2种模式。 无论是同步模式还是异步模式,swoole_http_server都可以维持大量TCP客户端连接。同步/异步仅仅体现在对请求的处理方式上。 示例: ```php <?php $http = new swoole_http_server("127.0.0.1", 9501); $http->on('request', function ($request, $response) { $response->end("<h1>Hello Swoole. #".rand(1000, 9999)."</h1>"); }); $http->start(); ``` #### 同步模式 这种模式等同于nginx+php-fpm/apache,它需要设置大量worker进程来完成并发请求处理。Worker进程内可以使用同步阻塞IO,编程方式与普通PHP Web程序完全一致。 与php-fpm/apache不同的是,客户端连接并不会独占进程,服务器依然可以应对大量并发连接。 #### 异步模式 这种模式下整个服务器是异步非阻塞的,服务器可以应对大规模的并发连接和并发请求。但编程方式需要完全使用异步API,如MySQL、redis、http_client、file_get_contents、sleep等阻塞IO操作必须切换为异步的方式,如异步swoole_client,swoole_event_add,swoole_timer,swoole_get_mysqli_sock等API。 个人认为最后这段引用是非常具备价值的,仔细品读或许能够从中得到一些感悟。我在前面曾经写过一篇[swoole的进程模型 ](https://blog.ti-node.com/blog/6379580337835474944 "swoole的进程模型 "),实际上你可以这么理解,就是master进程可以hold住上万个TCP连接是没有任何问题的,因为master进程内部异步非阻塞的,但是仅仅hold住上万个TCP连接本身是没有任何意义的,因为有数据传输的TCP连接才是有意义的。一旦有数据传输就意味着有业务逻辑产生了,那么master进程并不负责具体业务逻辑代码了,处理这个业务逻辑的活儿交给worker进程来干,然后干完后再由master进程返回给客户端。 同步阻塞模式下,如果说worker进程1秒钟完成1个客户端的业务逻辑,尽管master进程同时hold住了1W个TCP连接,但是1个worker进程只能服务于1个客户端,1W个客户端全部处理完毕,需要1W秒钟。所以,同步阻塞模式下,如果你想干活猛,就只能增加worker进程的数量,比如1000个甚至2000个。当然了,看到这里有为青年就会提出问题了,这样一味地增加进程数量岂不是意味着进程再多的话进程间切换都是极为耗费CPU的?是的,所以很简单,横向扩展加机器就是了... ...或者,选择异步。 异步非阻塞模式下,这个时候除了master进程是异步非阻塞外,要求worker进程中的业务逻辑代码也得是异步非阻塞工作的方式。也就说worker进程在处理1个客户端业务逻辑的时候,如果没处理完毕就会立马开始处理第2个客户端的业务逻辑,然后继续第3个... ...持续...一旦某个客户端的业务逻辑处理完毕了就有回调通知,从此可以做到即便只有少量worker进程但依然可以维持高速高效地处理速度。所以,这种情况,对编写业务逻辑代码就有了很高的要求了。假如业务逻辑就是“插入1条评论,然后返回最新5条评论”,用伪代码演示如下: ```php <?php // 你要创建异步的MySQL客户端,而不是普普通通的pdo mysqli $async_mysql = new async_mysql(); $async_mysql->on( 'connect', function( $async_mysql ){ echo '连接成功'.PHP_EOL; // 插入评论 $sql = "insert into pinglun() values()"; $async_mysql->query( $sql, function( $async_mysql, $result ) { // 如果插入成功 if( true == $result ){ // 获取5条最新评论 $sql = "select * from pinglun limit 5"; $async_mysql->query( $sql, function( $async_mysql, $result ){ // 获取成功后拿数据 if( true == $result ){ print_r( $result->fetchAll() ); } else { echo "获取失败".PHP_EOL; } } ); } // 如果插入失败 else { echo "插入数据失败".PHP_EOL; } }); } ); ``` 这种代码里,将不可避免地产生大量的类似于on这种回调,如果再有一些条件依赖话,可能不得不层层回调。比如插入最新评论需要依赖connect,只有connect成功了才能执行插入操作,然后是查询最新5条评论功能依赖插入操作,只有插入操作成功才能继续查询5条最新评论。最重要的是,需要IO操作的这些函数等等都必须得是异步的才行,传统的pdo、mysqli是统统不可以用的。因为只要有一处是同步阻塞了,整个worker进程中的业务逻辑代码就算是彻底完蛋沦为同步阻塞了。所以说,如果你要在这种代码里用sleep( 100 ),你会死得惨烈。 “没有这金刚钻,别拦这瓷器活”... 如果说我们用传统的同步阻塞代码的话,伪代码大概如下你们感受一下: ```php <?php $pdo = new pdo(); try { $pdo->connect( $host, $port ); $pdo->query( "insert into pinglun() values()" ); $pdo->query( "select * from pinglun limit 5" ); } catch( Exception $e ) { throw new Exception('error.'); } ``` 爱不爱?喜不喜欢?高不高兴?而且我还能任意写sleep... ... 当了这么多年的同步阻塞fpm(同步阻塞apache)的CURDer你跟我说你天生就爱异步?你猜我信么?  但是,异步带来的QPS上的提升实在是太明显了(注意,异步并不能提高性能,只是能提高QPS。性能就在那里躺着呢,该是多少就是多少,只不过异步可以更好的挖掘和压榨,并不能提高TA),但异步的代码实在是难写,辣么,有没有一种既可以用同步阻塞这种风格写的背后又是异步方式的方法呢?废话,当然有,不然我要这文章有何用?这种东西就是协程! 其实,有为青年在研究Golang的时候早就已经开眼见世界了,那是身经百战见的多了,但是像我这样的蠢货萌新自然是不知道的。一些人用php的yield来实现协程,不过,我认为swoole的协程要比这个yield好很多。简单说起来,协程这个东西就是用户态的异步IO,也就说不需要操作系统参与的,这点儿上和真正的异步IO的概念是不一样的。因为严格扣定义的话,异步IO是操作系统内核实现并参与的,现在协程并不需要系统参与,仅仅用户层就可以解决这些问题。 废话不多说,还是通过代码来感受一下,这坨代码大概意思就是开了一个http服务器,开了一个worker进程,worker进程中业务逻辑代码就是往数据库里添加一条记录,你们感受一下: #### 首先,注释掉同步阻塞传统代码,使用协程的写法;其次,注释掉协程写法,开启同步阻塞写法。然后分别使用ab进行简单测试 - ab -n 5000 -c 100 -k http://127.0.0.1:9501/ - 只开了一个worker进程 - 数据表你们自己建吧,我就不贴出来了 ```php <?php $server = new Swoole\Http\Server('127.0.0.1', 9501 ); $server->set( array( 'worker_num' => 1, ) ); $server->on('Request', function($request, $response) { // 数据库插入一条数据 $sql = "insert into user(`name`) values('iwejf')"; // 下面这段是传统的同步阻塞写法 /* $dbh = new PDO('mysql:host=localhost;dbname=meshbox', 'root', 'root'); $dbh->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); $dbh->exec('set names utf8mb4'); $rs = $dbh->query($sql); */ // 下面这段是协程的写法 $mysql = new Swoole\Coroutine\MySQL(); $res = $mysql->connect([ 'host' => '127.0.0.1', 'user' => 'root', 'password' => 'root', 'database' => 'meshbox', ]); $ret = $mysql->query( $sql ); // 回应客户端ok $response->end("ok"); }); $server->start(); ``` #### 这里是协程的测试结果: 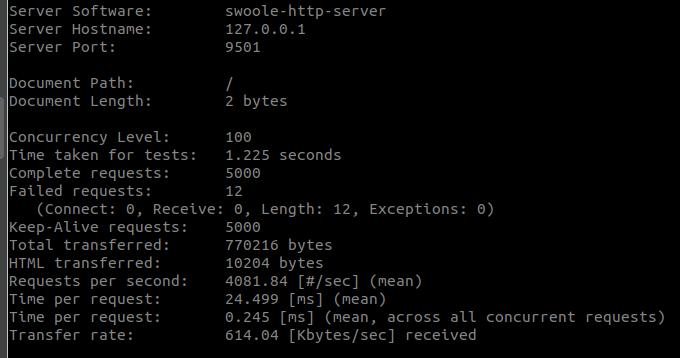 #### 这里是传统同步阻塞的测试结果: 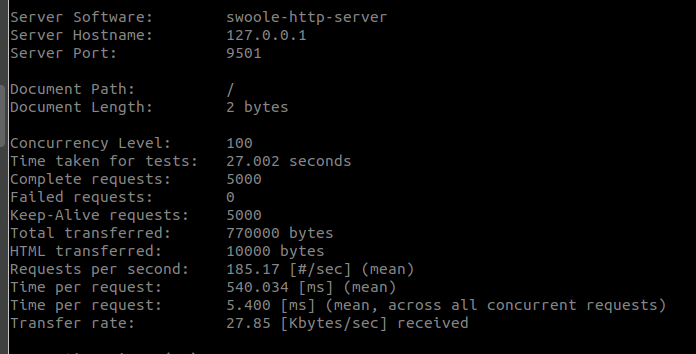 测试结果我们就不分析了,你们应该能看懂。这中间巨大的QPS差距你们应该能感受到了。话说回来,由于我们知道想提高同步阻塞代码的QPS最有效的办法就是增加进程数量,因此我们将woker进程数量调整为8,再测试一把:  继续调整为16:  继续调整为32(接近协程的成绩,但依然差了1000QPS):  继续调整为64(终于超过单进程协程1600QPS了):  最终结果就是,我们用同步阻塞的模型开启了64个进程大概可以超越开启1个进程的协程方式将近1600QPS。 最后,部分有为青年可能想要了解swoole协程原理,我自己因为水准问题(其实我不懂)就不发表自己的看法了,直接盗链官网资料了:https://wiki.swoole.com/wiki/page/p-coroutine_realization.html
