/首页
/开源
/关于
接着搞【附近】---Elasticsearch还是Postgre?(四)
发表@2019-09-19 08:34:54
更新@2023-01-21 22:47:40
果不其然,第三篇出去后就有很多人在问我为毛没有PostGIS,其实我内心的小算盘是:如果你们不提这玩意我就不写了,你们提了我就安排到后面补充一下。 然而,我是一定要写一下ElasticSearch的,我认为这玩意现在在此系列文章中这个节点上出现的意义要比Postgre重要。原因有如下几条: - 个人认为,ES不是数据库 - Postgre是数据库 - Postgre应该去 VS Mongodb 或者 VS MySQL - 应该接触一下ElasticSearch与数据库们的使用搭配方式,他们之间如何互补的,方便以后出去面试骗到一个稍微高点儿的工资 当然了,为了提升整体这一系列文章的气质和气势,我也是一定要表演一波儿这个上市大公司的究极作品。实际上早在积目的时候,总用户量一破百万,咱就将MongoDB切成了Elasticsearch,这玩意搞多条件综合查询真是如拉肚子时一般顺畅。虽然咱老李在MOMO时间短而且人微言轻、说了不算、没人鸟,但咱在积目那真的是:  不过说正经的,当时为啥从MongoDB切Elasticsearch,原因大概有如下几条: - 一来是多接触多学习多见识瞎折腾 - 二来是【附近】实际上是一个多条件的搜索,不单单靠经纬度,所以用MongoDB搞多条件,我是不相信它能PK过Elasticsearch的 首先说来,得先摆正Elasticsearch和数据库之间的关系。在咱看来,Elasticsearch并不是数据库,虽然它能存储数据而且有着较为客观的IO性能,但是它的准确定位应该是搜索引擎。一定程度上讲,这种东西就为了增强传统数据库的搜索能力而存在的。更常规用法应该是数据落地存储依然需要数据库,抽取需要的数据维度放到Elasticsearch中实现业务中需要搜索需求。 <center><font color=red>我发现实在是说不清,所以还是发个图吧</font></center> 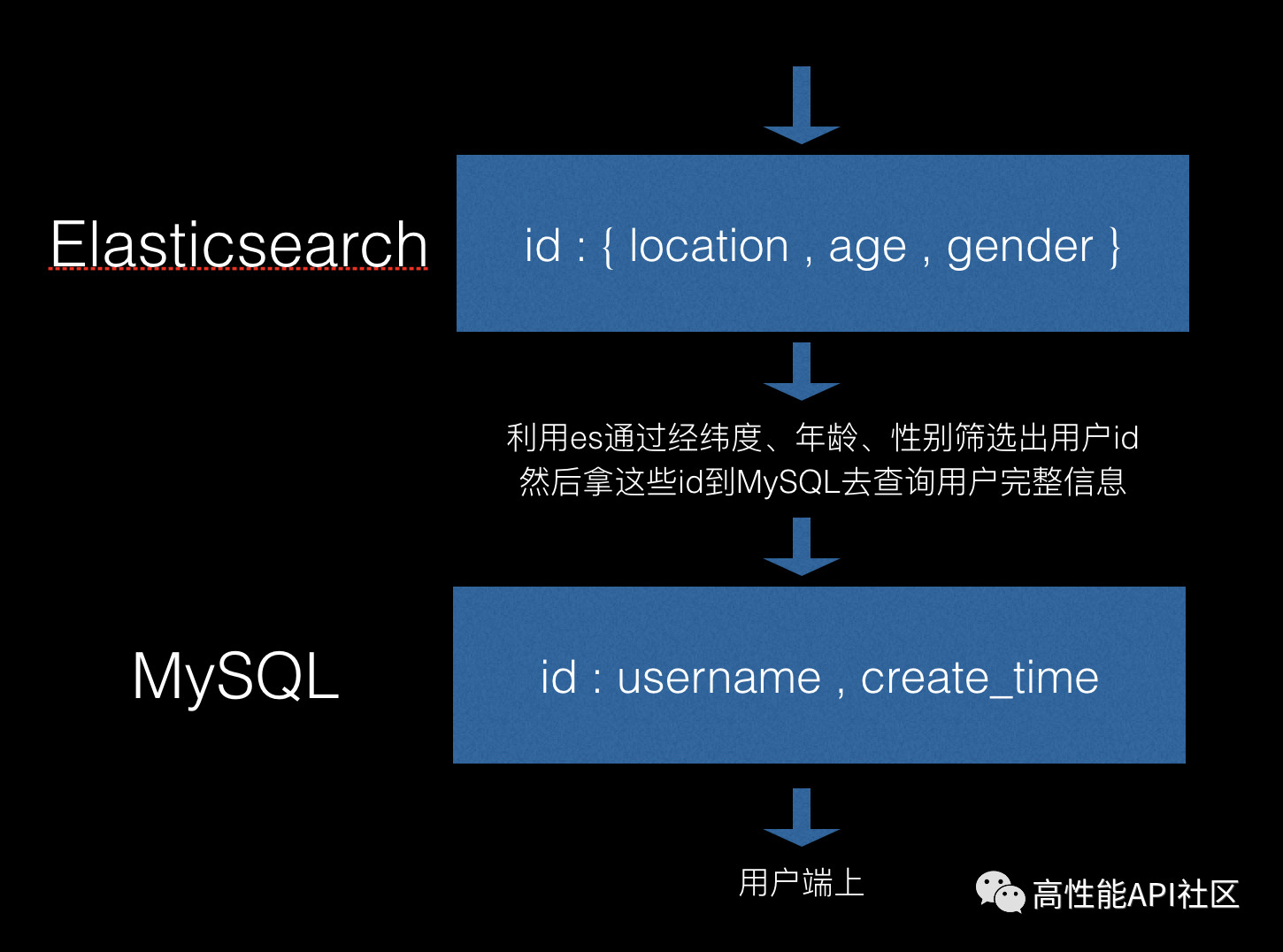 一般说平时我们用数据库查询数据都是下面这样shai儿: ```php select * from user where uid = 'xiaodushe' ``` 这是一种典型的根据记录(文档?)ID去查询记录(文档?)的做法,术语叫做正向索引。正向索引往往就是你已经知道要找的是谁了,你直接根据TA昵称去揪TA。比如老李,旅长指名道姓要找他,那就很精确的来一个电报: ```php select * from tiantuan where name = '老李' ``` 如果说突然阎老西要跨界借调我党的优秀团长,那么阎老西很有可能并不知道老李这号人,所以一般说此时此刻阎老西得通过关键词来找满足条件的人,当然了满足条件有可能只有一个,也有可能是一坨。比如阎老西的参谋长给阎老西的关键词有如下几个: - 泥腿子 - 曾经服役于独立团 - 行军途中曾经背过炊事班的黑锅 - 年轻时是十里八乡有名的俊后生 - 曾经从事过编筐篾匠手工艺行业 要从一个人的描述中找出这三个关键字,对于MySQL等数据库来说实在是强人锁男。总不能写下面这种语句吧: ```php select id from user where description like '%行军途中曾经背过炊事班的黑锅%' or description like '%年轻时是十里八乡有名的俊后生%' or description like '%曾经从事过编筐篾匠手工艺行业%' ``` <center><font color=red>弄不好还真能用,你要敢这么用,就有人会打死你</font></center> 然而合理的做法的应该是这样的,比如说候选人物一共三个,然后将三个人的description进行关键词分词,我来编写一个下三个人的description你们感受一下: - 丁炸桥:曾经和老李在一个班服役,一度说过学习学个屁啊,泥腿子 - 孔过瘾:差点儿被山本端了老窝,泥腿子,曾经服役于独立团 - 老李:曾经从事过编筐篾匠手工艺行业,年轻时是十里八乡有名的俊后生,行军途中曾经背过炊事班的黑锅,泥腿子,曾经服役于独立团 关键词分词(自然语言的分词处理是一门高深学问,关键字是NLP)完毕后,变成这样的: ```php 曾经和老李在一个班服役 =》 丁炸桥 一度说过学习学个屁啊 =》 丁炸桥 泥腿子 =》 丁炸桥,孔过瘾,老李 差点儿被山本端了老窝 =》 孔过瘾 曾经服役于独立团 =》 孔过瘾,老李 曾经从事过编筐篾匠手工艺行业 =》 老李 年轻时是十里八乡有名的俊后生 =》 老李 行军途中曾经背过炊事班的黑锅 =》 老李 ``` 阎锡山拿着五个关键字开始搜人,然后将每个关键字的结果做一交集: ```php 泥腿子 = {丁炸桥,孔过瘾,老李} 曾经服役于独立团 = {孔过瘾,老李} 曾经从事过编筐篾匠手工艺行业 = {老李} 年轻时是十里八乡有名的俊后生 = {老李} 行军途中曾经背过炊事班的黑锅 = {老李} 将五个结果集交集运算,得出一个最终结果集,当然这个结果集里只有一个人:老李。 ```    <center><font color=red>这就是传说中的反向索引(有地方叫倒排索引)</font></center> 反向索引是Elasticsearch的根基与精髓,我们用ES绝大多数情况下为的就是反向索引。不过此处需要提醒,上面是为了说明反向索引的流程,而在我们搞【附近】这个大型跨平台分布式微服务项目中,我们直接在ES里建立好搜索条件维度即可,比如性别、年龄、经纬度只需要在ES里做好精确搜索即可。 <center><font color=red>我们需要CV Code,不是BB粗暴原理</font></center> ------------ <center><font color=red>安装ES</font></center> Elasticsearch是由世界上最棒的语言Java编写的,这玩意是基于著名搜索引擎Lucene构建而成的,那为啥不用Lucene?因为太难用了。ES牛逼的地方在于他提供了基于HTTP协议的接口,也就是说这玩意安装完毕后你就可以通过HTTP方式对TA进行各种CURD了。 <center><font color=red>世间一切皆为CURD</font></center> 按说安装这个问题我真的是不能说了,不过考虑到我也得安装,所以我顺带把Mac环境下ES的安装步骤简单说下,其他平台的你们自己搞定: ```php brew install elasticsearch brew services start elasticsearch // 然而默认服务启动后,IP是监听在127.0.0.1:9200上 // 所以配置需要修改一下 sudo vim /usr/local/etc/elasticsearch/elasticsearch.yml // 找到network.host: 127.0.0.1 // 修改成你自己的IP地址 // 重启ES服务 brew services restart elasticesearch // 确认下服务状态? netstat -ant | grep 9200 ``` ------------ <center><font color=red>创建数据结构</font></center> 这次我们要根据经纬度、性别、年龄三个维度去搞【附近】,我们要搞的第一件事就是从github.com上扒一个ES库,比如这个: <center><font color=red>https://github.com/elastic/elasticsearch-php</font></center> 第一步、在ES中创建好索引。说创建索引可能会有一些歧义,这里我依然用数据库和数据表以及字段的概念来说明。比如下面这个curl HTTP调用,就是在ES中创建一个数据库叫做momo,其中一个数据表叫user,user数据表中的字段有如下三个: - age:类型为整形,表示用户年龄 - gender:类型为整形,表示为性别,1女2男 - location:类型为geo-point,表示为经纬度 ```php curl -X PUT \ http://192.168.199.225:9200/momo \ -H 'Accept: */*' \ -H 'Cache-Control: no-cache' \ -H 'Connection: keep-alive' \ -H 'Content-Type: application/json' \ -H 'Host: 192.168.199.225:9200' \ -H 'Postman-Token: d4c2303e-983d-49a9-a7d4-79f2b78ea6a3,4913986c-8cbe-4439-b7fd-80794b2a0bdc' \ -H 'User-Agent: PostmanRuntime/7.15.0' \ -H 'accept-encoding: gzip, deflate' \ -H 'cache-control: no-cache' \ -H 'content-length: 361' \ -d '{ "mappings" : { "user" : { "properties" : { "age" : { "type" : "integer" }, "gender" : { "type" : "integer" }, "location" : { "type" : "geo_point" } } } } }' ``` 如果没什么大问题的话,就会返回下面这个创建成功的提示: ```php { "acknowledged": true, "shards_acknowledged": true, "index": "user" } ``` 第二步、用前面的PHP ES库往ES里存入1000条数据,方便我们进行第三步的查询: ```php <?php require 'vendor/autoload.php'; use Elasticsearch\ClientBuilder; $client = ClientBuilder::create()->setHosts( array( '192.168.199.225' ) )->build(); /* // 删除一条数据 $params = [ 'index' => 'momo', 'type' => 'user', 'id' => 1 ]; $response = $client->delete( $params ); print_r( $response ); exit; */ // 造1000个假数据 for( $i = 1; $i <= 1000; $i++ ) { // 生成一个维度 $lat = mt_rand( 38, 40 ).'.'.mt_rand( 100000, 999999 ); // 生成一个经度 $lon = mt_rand( 115, 116 ).'.'.mt_rand( 100000, 999999 ); $params = array( 'index' => 'momo', 'type' => 'user', 'id' => $i, 'body' => array( 'age' => mt_rand( 18, 25 ), 'gender' => mt_rand( 1, 2 ), 'location' => array( 'lat' => $lat, 'lon' => $lon, ), ), ); $response = $client->index( $params ); print_r( $response ); } ``` 保存为index.php,然后命令行里输入php index.php执行一下,结果如下,你们感受一下:  第三步、开始执行查询,我们要按照距离由远到近寻找一下我们附近的性别为2、年龄在18岁到25岁之间的目标,假如我所在的经纬度是【116.324356,39.972023】: ```php <?php require 'vendor/autoload.php'; use Elasticsearch\ClientBuilder; $client = ClientBuilder::create()->setHosts( array( '192.168.199.225' ) )->build(); $params = array( 'index' => 'momo', 'type' => 'user', 'body' => array( 'query' => array( // bool "bool" => array( "must" => array( "match" => array( 'gender' => 2, ), ), "filter" => array( "range" => array( "age" => array( "gte" => 18, "lte" => 18, ), ), ), ), // bool END. ), // query END. 'sort' => array( '_geo_distance' => array( "location" => array( 'lat' => 39.972023, 'lon' => 116.324356, ), 'order' => 'asc', 'unit' => 'km', 'distance_type' => 'plane', ), ), // sort END. ), // query END ); $response = $client->search( $params ); foreach( $response['hits']['hits'] as $key => $item ) { echo "用户ID:{$item['_id']},性别:{$item['_source']['gender']},年龄:{$item['_source']['age']},距您:{$item['sort'][0]}KM".PHP_EOL; } ``` 上面代码保存成find.php,然后命令行里php find.php执行一把,结果如下,你们感受一下: 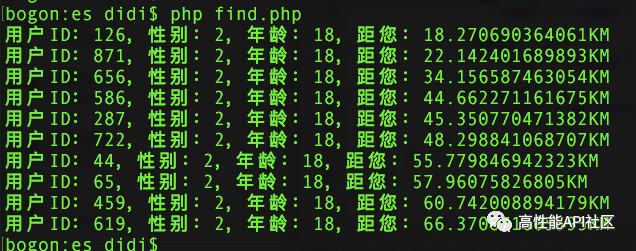 对于一个业务系统而言,最重要的是我们根据如下三个条件利用反向索引查询到了10个满足条件的用户uid: - age - gender - location 下面我们要做的就是拿着这10个用户UID去查询详细用户数据然后按照业务逻辑规则展示给前端UI。 说到这儿,我给大家说个十分有意思的事儿,这还是刀爷说的。那天刀爷在群里说他们公司(三驾马车之一)一个小伙儿搞业务,直接把ES当数据库查询用。结果晚上量起来了,崩了。这里说的拿ES当高并发数据库查询用是指根据用户UID查询用户信息,这家伙把用户数据存到了ES里。所以说简单总结一下: - 不要拿ES当高性能数据库用 - 不要拿MySQL们当搜索引擎用 这二者需要在业务系统里结合起来使用,才能发挥到最大威力。 ------------ 老规矩,代码我依然放到了github上,地址为: https://github.com/elarity/wechat-official-accounts-demo-code 为了敢在今天把稿子发出去,我还晾了杨老师一个小时,我特马容易吗?卧槽!
